
The AI you fell in love with may not be the AI you are married to.
I ran 43 tests against every GPT-4 variant I could get my hands on. The results made me uncomfortable.
[Updated December 3, 2025: I have extended this analysis to include GPT-5 and GPT-5.1. The results reveal a U-shaped recovery pattern. See the new section below.]
Something strange has been happening with GPT.
Long-time users have been complaining on forums and social media that the AI feels "dumber" than it used to be. Developers report that code suggestions that once worked flawlessly now come back broken. Researchers notice that math problems the model used to ace are suddenly producing wrong answers.
At first, I dismissed these complaints as the usual tech grumbling. Maybe people were just noticing limitations they had previously overlooked. Maybe the honeymoon period with AI had simply ended.
Then I ran the numbers myself. What I found should concern anyone who relies on AI tools for serious work.
The pachinko problem
To understand what might be happening, consider a business model from Japanese gambling halls.
Pachinko parlors are notorious for a specific pattern. When you first sit down at a machine, you often win. The balls cascade, the lights flash, and you think you have figured something out. But keep playing, and the wins gradually dry up. The machine has been calibrated (well... hammering the nails in the old days) to hook you with early rewards, then slowly tighten the odds.
Players keep chasing that initial high. The house profits from their optimism.
This pattern, sometimes called "bait and switch," appears across many industries. Mobile games give you easy victories in early levels before ramping up difficulty and pushing in-app purchases. SaaS companies offer generous free tiers that quietly shrink once you have built your workflow around them. Streaming services launch with low prices that creep upward after you have accumulated years of watch history.
The question is whether something similar is happening with large language models.
What "nerfing" actually means
In gaming communities, "nerfing" refers to weakening a character or weapon through software updates. Players who relied on a particular strategy suddenly find it no longer works.
In the AI context, users have borrowed this term to describe a perceived decline in model quality over time. But what could actually cause an AI to get worse?
Several mechanisms are plausible:
- Quantization reduces the precision of a model’s internal calculations. Instead of storing numbers with 16 bits of precision, you might use 8 bits or even 4 bits. This dramatically cuts the memory and compute required to run the model. The tradeoff is often small but real accuracy changes, which can show up first in tasks that need precise reasoning or attention to detail.
- Architecture changes can also affect performance. OpenAI is rumored to use a "Mixture of Experts" approach for some models, where different specialized sub-networks handle different types of queries. This can reduce costs but may introduce variability in output quality.
- Safety fine-tuning and content filters adds guardrails to prevent harmful outputs. This is often necessary and valuable, but aggressive tuning can make models more cautious, more likely to refuse requests, and sometimes less helpful on legitimate tasks.
- Backend switching is perhaps the most opaque. When you call an API labeled "GPT-4," you assume you are getting GPT-4. But the specific version, infrastructure, and configuration behind that label can change without notice.
From the outside, all these mechanisms produce the same observable effect: the AI behaves differently than before. Sometimes worse, sometimes just different, but definitely not stable.
Testing the hypothesis
As a researcher, I am trained to be skeptical of claims that lack data. So I built a small but careful benchmark to test whether model quality has actually declined.
The test suite includes 43 prompts across seven categories:
- Strict formatting tasks (exact JSON output, CSV headers)
- Basic arithmetic (simple operations requiring integer-only answers)
- Harder arithmetic (multi-step calculations)
- Counting tasks (letters in words, using novel words to avoid memorized examples)
- Prime number classification (including a replication of a Stanford/UC Berkeley methodology)
- Edge cases (zero handling, empty inputs, division scenarios)
- Chain-of-thought reasoning tasks
I deliberately avoided viral examples like "How many R’s in strawberry?" that models might have been specifically trained on. Instead, I used uncommon words like "peripherally," "nevertheless," and long medical terminology.
All tests ran with temperature set to zero and a fixed random seed. This minimizes randomness and makes any differences more likely to reflect actual model changes.
I tested eight OpenAI models:
- GPT-4 and GPT-4-0613 (the June 2023 snapshot)
- GPT-4-turbo and GPT-4-turbo-2024-04-09
- GPT-4o (the current alias) and three dated snapshots
The results were striking.
The numbers tell a story
GPT-4 (June 2023 snapshot): 37 out of 43 correct (86%)
This is the model that captured the world’s imagination. It follows instructions precisely, formats outputs correctly, and handles edge cases reliably.
GPT-4-turbo: 20 out of 43 correct (46.5%)
A 40-percentage-point drop. The "turbo" variant, marketed as faster and cheaper, gets less than half the test suite correct.
GPT-4o variants: 27 to 30 out of 43 correct (63% to 70%)
Better than turbo, but still 16 to 23 percentage points below the original GPT-4. The good news is that later GPT-4o snapshots show gradual improvement. The bad news is that even the best GPT-4o snapshot has not recovered to GPT-4 levels on these tasks.
| Model | Accuracy | Notes |
|---|---|---|
| GPT-4 (June 2023) | 86% | Original release |
| GPT-4-turbo | 46.5% | 40-point drop |
| GPT-4o variants | 63-70% | Partial recovery |
| GPT-5 (August 2025) | 86% | Full recovery |
| GPT-5.1 (November 2025) | 95.3% | New peak |
Critical insight: Here is the pattern that matters most: the regression is primarily in instruction following, not knowledge.
When I asked GPT-4-turbo to "compute (999 minus 456) times 3 and respond with the integer only," it often gave the correct mathematical answer but wrapped it in explanatory text. From a pure knowledge standpoint, it "knew" the answer. From a practical standpoint, it failed the task.
Of course, this is a small, targeted stress test focused on instruction-following, math, and counting. I am not claiming that GPT-4-turbo or GPT-4o are worse on every dimension. They may be faster, cheaper, or better at other tasks like conversation or coding. But for anyone building systems that depend on structured outputs, that distinction does not matter. A wrong format is operationally wrong.
The Stanford/Berkeley study that started this conversation
My findings align with research from Stanford and UC Berkeley published in 2023. Chen, Zaharia, and Zuo compared GPT-4’s behavior in March 2023 versus June 2023 on identical prompts.
On a simple prime number classification task with chain-of-thought prompting, GPT-4’s accuracy dropped from 97.6% to 2.4% over just three months. In my own tests, all current GPT-4 family models achieved only 38% on a similar chain-of-thought prime subset, suggesting that this degradation in reasoning behavior has persisted across later versions as well.
Let that sink in. The same prompt, the same "GPT-4" label, but accuracy fell by 95 percentage points.
The researchers also found that GPT-4 became more likely to refuse sensitive questions and less likely to produce immediately executable code. These changes were not announced. Users had no way to know the model they were paying for had fundamentally changed.
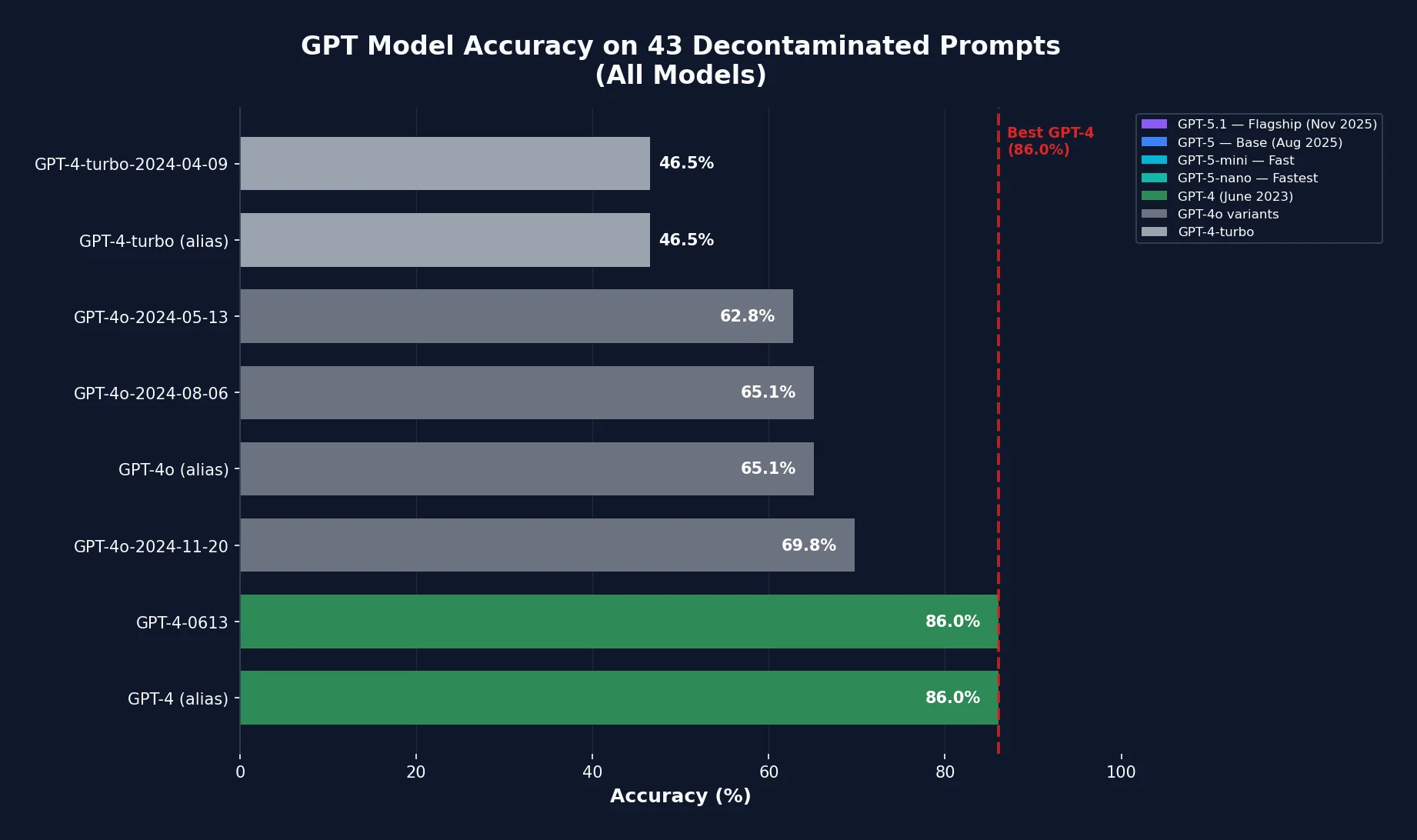
Accuracy across GPT model versions shows a distinct U-shaped pattern
December 3, 2025 update: The U-shape
I originally stopped my analysis at GPT-4o. Readers pushed back. "Why are you testing old models? GPT-5 is out. Try that."
Fair point. So I did.
GPT-5, released August 2025, scores 86.0% on my benchmark. That is identical to the original GPT-4 from June 2023. The model has finally climbed back to where it started.
GPT-5.1, released November 2025, scores 95.3%. This is the new peak. For the first time, a production OpenAI model has decisively surpassed the original GPT-4 on instruction-following tasks.
The pattern is not a straight line down. It is a U-shape.
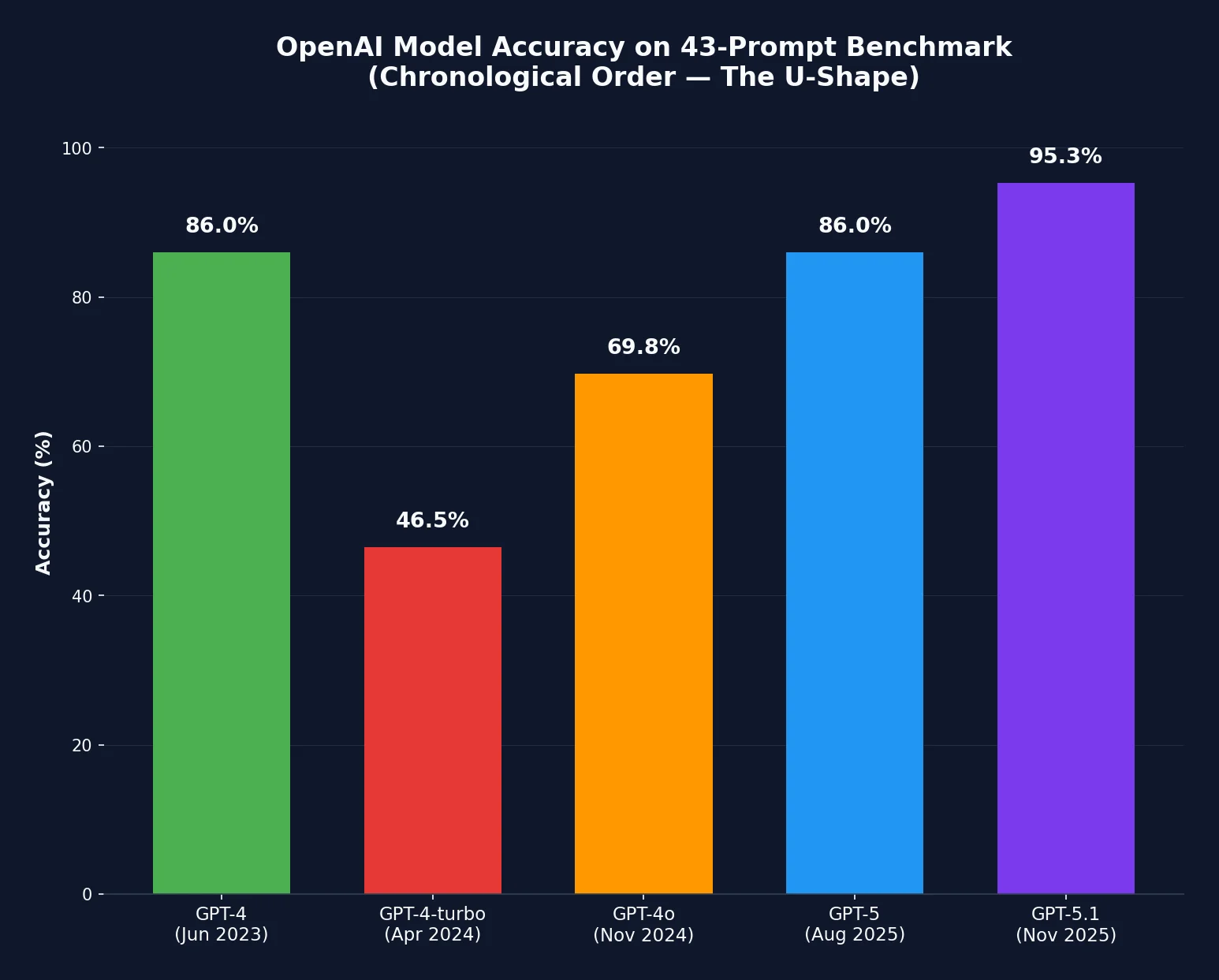
The U-shaped recovery pattern when viewed chronologically
Here is what that U-shape means for enterprises
If you adopted AI tools in early 2023, you got the sports car. If you kept using those tools through 2024, you silently got downgraded to a delivery van. If you are still using them today, you have been upgraded again to something even better than the original.
But you were never told about any of these changes.
The model behind your "GPT-4 powered" enterprise tool changed at least four times. Your vendor did not notify you. Your regression tests, if you had any, might have caught it. Most organizations did not have regression tests.
This is the governance failure I have been writing about. The problem is not that AI got worse. The problem is not that AI got better. The problem is that AI changed, repeatedly, and the systems that should have detected those changes did not exist.
Why this matters for business
The U-shape recovery is reassuring for capability. It is not reassuring for governance. Let me make this concrete.
If you are using Microsoft Copilot, you probably know it runs on GPT-4. What you likely do not know is which GPT-4. The June 2023 snapshot? The turbo variant? Some internal Microsoft version that has been further fine-tuned?
Microsoft does not publish these details. Neither does any other major enterprise AI vendor. You are trusting a black box to remain stable.
Consider the implications:
- Financial modeling: If your team uses AI to check spreadsheet formulas or validate calculations, a 40% drop in instruction-following accuracy means more errors slipping through. When your AI assistant was first deployed, it might have correctly flagged circular references or formula inconsistencies. Six months later, the same queries might produce confident but incorrect responses.
- Contract analysis: If your legal team uses AI to extract specific clauses and format them in a particular way, inconsistent output formatting creates manual rework at best and missed terms at worst.
- Audit procedures: If internal audit is using AI to process documentation, changing model behavior between audit periods makes it harder to demonstrate consistent methodology.
- Compliance reporting: Regulatory bodies expect reproducible processes. An AI that behaves differently each quarter is not reproducible by definition.
The fundamental problem is that enterprises have adopted AI tools as if they were traditional software. Install once, update on a schedule, test before deployment. But cloud AI does not work that way. The "software" changes underneath you without notice, without release notes, without regression testing.
Compliance implications: a deeper look
For professionals in accounting, finance, and tax, the implications of unstable AI behavior deserve particular attention. Let me unpack each domain.
Financial reporting and IFRS compliance
Under International Financial Reporting Standards (IFRS), management must make judgments and estimates that are reasonable and supportable. If AI tools are used to support those judgments, for example in impairment testing, lease classification, or revenue recognition analysis, the reliability of the AI becomes part of the audit trail.
Consider a scenario where your finance team uses an AI assistant to analyze contract terms for IFRS 15 revenue recognition. The AI might correctly identify performance obligations in Q1, but after a silent backend update, it might miss or misclassify similar obligations in Q2. If you cannot demonstrate that the tool behaved consistently, or that you tested for consistency, you have a documentation problem.
Regulators around the world have been actively developing AI governance frameworks. Their guiding principles generally emphasizes that financial institutions should be able to explain AI-driven decisions. Explaining a decision becomes considerably harder when the underlying model has changed without your knowledge.
Audit quality
For auditors following International Standards on Auditing (ISA), the use of AI tools raises questions about audit evidence and professional skepticism.
ISA 500 requires that audit evidence be sufficient and appropriate. If an auditor uses AI to analyze a population of transactions, and the AI’s classification accuracy has silently degraded, the sufficiency of the evidence is compromised. The auditor may believe they have tested 100% of a population when in fact they have tested 60% correctly and 40% incorrectly.
ISA 220 on quality management requires firms to have policies addressing the use of technology. Those policies should now explicitly address model versioning and behavioral drift. An audit firm that cannot demonstrate it monitored for AI quality changes is exposed to quality control questions.
For internal auditors following the International Professional Practices Framework (IPPF), the same concerns apply. If AI is part of your continuous monitoring or data analytics capability, you need evidence that the AI itself was functioning as expected during the audit period.
Tax compliance
Tax compliance presents unique challenges because of its rule-based nature. Tax computations often require precise application of specific rules to specific facts. Tax authorities expect taxpayers to maintain adequate records and apply tax rules correctly.
If your organization uses AI to assist with GST classification, corporate tax computations, or transfer pricing documentation, model degradation can introduce errors that are difficult to detect. A model that correctly classified transactions as standard-rated versus exempt in 2023 might start making subtle errors in 2024, leading to under-reporting or over-reporting of GST.
Transfer pricing is particularly sensitive. The arm’s length principle requires careful analysis of comparable transactions. If AI is used to identify comparables or analyze pricing, and the model’s analytical capability has degraded, the resulting transfer pricing documentation may not withstand tax authority scrutiny.
For cross-border tax planning, where Singapore serves as a regional hub for many multinationals, the stakes are even higher. AI-assisted analysis of treaty benefits, permanent establishment risks, or withholding tax obligations requires consistent and reliable model behavior.
Anti-money laundering and sanctions compliance
Financial institutions face tightening requirements. Many institutions have deployed AI-enhanced transaction monitoring and customer screening systems.
If the underlying model powering these systems degrades, the consequences can be severe. A model that correctly flagged suspicious patterns might start missing them after an update. Or worse, it might generate excessive false positives, leading to alert fatigue and genuine risks being overlooked.
Regulators expect financial institutions to validate their AML models regularly. But validation assumes you know what model you are testing. If your vendor can change the backend without notification, your validation results may be obsolete the day after you complete them.
The accountability gap
From a finance, accounting, and AI governance perspective, this creates a serious gap.
When you purchase traditional enterprise software, you receive a specific version with documented capabilities. You can test it against your requirements before deployment. You control when updates occur. If something breaks, you can roll back.
With cloud AI services, none of this applies. The model behind the API can change at any moment. You have no rollback capability for the parts you do not control. The vendor’s incentives (reduce costs, improve safety metrics, release new features) may not align with your need for stability.
This is not theoretical. In a June 2023 update, OpenAI themselves wrote that "while the majority of metrics have improved, there may be some tasks where the performance gets worse," and explicitly recommended version pinning for stability. That version pinning exists is itself an admission that the current alias is not stable.
For listed companies subject to the exchange listing rules, there are disclosure considerations as well. If AI is material to your operations or risk management, and the AI’s reliability is uncertain, should that be disclosed as a risk factor? Stock exchange has been increasingly focused on technology risk disclosure, and AI model stability fits squarely within that concern.
What businesses should do
For any organization that depends on AI for consequential tasks, here are concrete steps to take:
- Pin your model versions. If you are using OpenAI’s API directly, specify dated snapshots rather than aliases. Use "gpt-4-0613" instead of "gpt-4." Use "gpt-4o-2024-08-06" instead of "gpt-4o." This will not prevent all changes. Snapshots eventually deprecate. But it gives you control over when transitions occur.
- Build regression test suites. Create a small set of prompts that represent your actual use cases. Run these tests regularly and track accuracy over time. Even 20 to 30 carefully chosen examples can detect behavioral drift. The test suite I built is available for adaptation, and is simple enough to run in an afternoon but sensitive enough to catch the differences I documented.
- Require change notification in vendor contracts. If you are negotiating enterprise AI agreements, push for contractual requirements around: notification of model changes affecting your endpoints, access to changelogs and release notes, service level agreements tied to quality metrics not just uptime, and right to audit or benchmark the model serving your contract. A change in model behavior could also change how personal data is processed, even if the data flows remain the same.
- Treat AI services as dynamic processes, not static products. In your internal controls documentation, acknowledge that AI model behavior can change without explicit action on your part. Build monitoring and exception handling around this assumption. For organizations following the COSO Internal Control Framework or Enterprise Risk Management Framework, AI model stability should be part of your control environment assessment. The control "We use AI to review contracts" is incomplete without "and we monitor the AI for behavioral changes."
- Document your methodology with version specificity. If AI is part of your audit trail or compliance processes, record not just that you used "GPT-4" but the specific dated version, the system fingerprint if available, and the timestamp of execution. This is particularly important for regulated industries. If regulator asks how you arrived at a particular conclusion, "we used AI" is not a sufficient answer. "We used GPT-4-0613 with temperature 0 on 15 November 2024, and here is the exact prompt and response" is much better.
- Establish AI governance committees. For larger organizations, consider establishing cross-functional governance bodies that include representatives from IT, risk, compliance, finance, and business units. These committees should review AI deployments, monitor for quality issues, and establish policies for model changes. Even if you are not a financial institution, the principles are broadly applicable: accountability, explainability, fairness, and transparency.
- Consider open-source models for stability-critical applications. Open-weight models like DeepSeek, Llama, Kimi, or Mistral offer a different tradeoff. When you download and deploy these models yourself, the weights do not change unless you change them. You control the version completely. The downside is that self-hosting requires technical expertise and infrastructure, and open-source models may not match the capabilities of the leading proprietary models on all tasks. But for applications where consistency matters more than peak performance, running a fixed, versioned open-source model may be preferable to trusting a cloud API that can change without notice.
The broader picture
I want to be careful about what I am and am not claiming.
My data show that GPT-4-turbo and GPT-4o variants perform substantially worse than the original GPT-4 on a specific set of instruction-following and math tasks, while GPT-5 and especially GPT-5.1 recover and surpass GPT-4 on the same benchmark. This is consistent with user reports and with the Stanford/UC Berkeley findings.
My data do not prove that OpenAI deliberately degraded their models to save money. The changes could reflect legitimate safety improvements, architectural experiments, or unintended side effects of optimization. I have no visibility into OpenAI’s internal decisions.
What I can say with reasonable confidence is this: the model that enterprises are getting today is not the model that generated the hype in early 2023. Whether you call that "nerfing" or "optimization" or "normal product evolution," the practical effect is the same.
A note on methodology
For those interested in the technical details, here is how the benchmark works:
Each prompt has a single correct answer that can be verified algorithmically. For arithmetic, the answer must match the expected integer exactly. For formatting tasks, the output must match the expected string character-for-character. For yes/no classification, only "YES" or "NO" counts as correct.
Temperature is set to 0.0 for all calls, with a fixed seed where the API supports it. This reduces sampling randomness and makes differences more attributable to model changes.
For a deeper dive into LLM math capabilities, see my previous analysis: Large language models struggle with basic math.
What comes next
The AI industry is young, and norms around model stability are still forming. OpenAI, Anthropic, Google, and others are all navigating tradeoffs between capability, safety, cost, and reliability.
My hope is that enterprise customers will push for better transparency. Not because AI companies are malicious, but because the current opacity makes it impossible to make informed decisions about AI governance.
When you buy a Honda HR-V, you know what engine you are getting. When you buy a subscription to GPT-4, you might be getting anything from a sports car to a delivery van, and you will not know the difference until something breaks.
For accounting and finance professionals, that unpredictability is a control weakness. For audit committees, it is a risk factor. For anyone building AI into mission-critical workflows, it is a reason to invest in monitoring, version pinning, and contractual protections.
The pachinko machine keeps changing its odds. Sometimes the odds get worse. Sometimes they get better. The machine does not tell you either way. The question is whether you are paying attention.
Key takeaway: Model capability is not static. The U-shaped recovery pattern suggests capabilities eventually improve, but the governance gap between what you validated and what runs in production remains unresolved. Monitor, don’t assume.