Why this tutorial exists
Comparing two IBES Unadjusted Detail History drops (say a 2023 vintage vs. a 2025 vintage) looks trivial. In practice, it’s where many projects quietly go off the rails. Small, harmless changes in values, currency flags, names, and time-of-day stamps can make the same forecast event look "different" across vintages. And a naive merge will "discover" millions of spurious non-matches. That, in turn, can conclude that IBES anonymizes forecasts.
The fix is simple:
(1) put both vintages on the same information set (an as-of window), and
(2) merge on a stable event key that identifies the event, not its attributes.
This workflow is grounded in what we know about how IBES evolved in recent years:
- Since 2017Q1, IBES anonymization has primarily affected non-US forecasts, with negligible impact on US EPS forecasts. Recommendations were largely unaffected, which is why they can help diagnose or reverse-engineer anonymized IDs. (See Figure 1 for the time-series pattern and Tables 2-3 for US vs. non-US splits in the JFR paper.)
- Across two distant vintages (e.g., 2015 vs. 2021), large-scale ID reshuffling is not the norm: average reassignments are only a few percent, concentrated where analyst IDs were anonymized and later backfilled. (See Table 5 and discussion.)
- For cross-vintage identity checks, use Unadjusted files. Using Adjusted detail to match vintages mechanically creates "differences" after splits and will overstate non-matches. (Recommendations section and footnote discussion.)
Together, these facts justify the design choices below and explain why a careful merge often yields >99% overlap after basic hygiene. (The small residual is real and diagnosable, rather than a keying artifact.)
Identity vs. attributes
Think of each row as a library card for a forecast event. Identity should not depend on decorative details.
Identity (use in the key):
- Firm (use a stable firm id. For keys I standardize the IBES ticker as firm)
- Analyst ID (ANALYS)
- Fiscal period end (FPEDATS)
- Horizon (FPI)
- Measure (MEASURE, e.g., EPS)
- Estimate date (prefer STATPERS with ANNDATS as fallback)
Attributes (never in the key):
- Forecast VALUE (it can change with backfills or currency logic)
- Currencies/flags (CURR, REPORT_CURR, CURRFL)
- Company names/tickers as strings (CNAME, or arguably OFTIC)
- Time-of-day stamps (ANNTIMS, REVTIMS, ACTTIMS)
Those attribute fields often change across drops without implying a different event. Keying on them manufactures "missing" that isn’t real. The "identity vs. attributes" distinction is the single most important idea in this tutorial. And it is consistent with the documented history of anonymization, backfilling, and the relatively stable recommendation tape.
The 2 rules that prevent a lot of headaches
- Shared as-of window: Restrict both datasets to the same estimate-date cutoff (prefer STATPERS; fallback ANNDATS). This ensures you’re comparing what the earlier vintage could have contained.
- Stable analyst-event key:
{ firm, ANALYS, FPEDATS, FPI, MEASURE, estimate_date }This identifies the event. Everything else is metadata. Use it for analysis, not for identity.
A quick, readable recipe (Stata, ~45 lines)
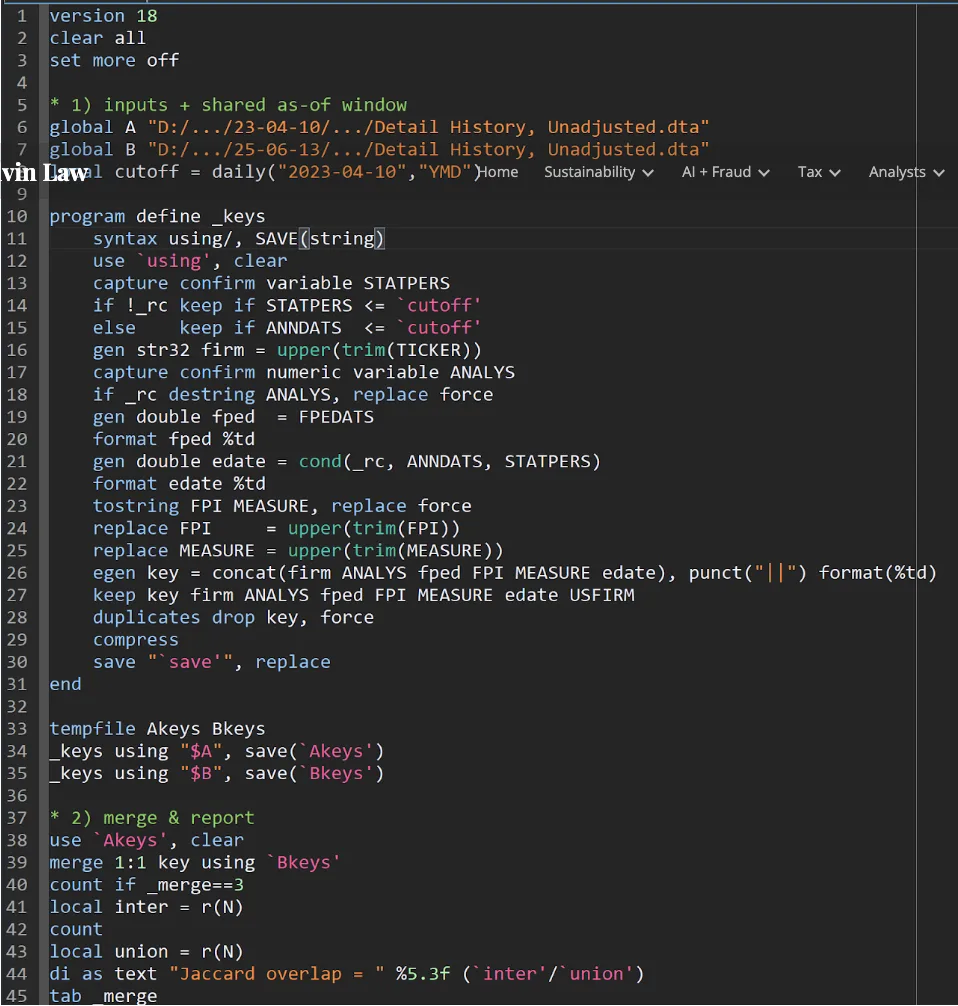
Let us run this.
What to expect? In large samples, the Jaccard overlap commonly exceeds 0.99 after these two steps. The remaining <1% is the diagnostic gold: structured, explainable differences we should label and (when relevant) carry into robustness checks.
The three things that usually explain the residual, and how to diagnose them
1) Tiny date refinements (±1 day)
It is common for estimate dates to shift by a day across releases as timestamps are cleaned or backfilled. Test a ±1 day tolerance on the estimate date while holding {firm, ANALYS, FPEDATS, FPI, MEASURE} fixed. If a large share reconciles, you’ve found the culprit.
How to test quickly (Stata tip): Use rangejoin (SSC) after you build a "short key" without edate, then match within ±1 day. (The goal is attribution, not creating a fuzzier main result.)
2) Analyst-ID maintenance / anonymization layer
Drop ANALYS from the key (i.e., move to the consensus level) and re-merge. If non-matches collapse, the issue lives in the analyst-ID layer: anonymization or maintenance that has been documented to primarily affect non-US forecasts after 2017Q1, with very little impact on US EPS forecasts and minimal changes in recommendations. (See Figure 1 and US vs. non-US tabulations in Tables 2–3.)
This is more than just housekeeping. Your paper’s research finding can sometimes depend on whether the instability is analyst-layer or event-layer. Let’s label it.
3) Firm-ID hygiene (especially non-US)
Tickers and display names are fragile. For diagnostics, create a hybrid firm id: CUSIP8 for US, SEDOL7 for non-US, else fall back to ticker. If mismatches fall when you use the hybrid, you are seeing identifier maintenance, not content loss. Keep your main key simple (firm), but report the diagnostic result.
Why this matters: US vs. non-US asymmetry in anonymization and that recommendations were largely unaffected. Hence they can help triangulate identity and even recover anonymized IDs in many cases. (See Table 3 for recommendations, and Table 4 for recovery rates.)
What not to do (and why)
- Do not key on VALUE or currency fields. They change for reasons that don’t mean a new event (currency normalization, backfills, rounding). You’ll inflate false "missing" or "anonymization."
- Do not mix Adjusted and Unadjusted when checking identity across vintages. Adjusted files account for splits, so the same forecast can have different values across drops. You’ll "find" differences that are purely mechanical. Use Unadjusted for vintage identity, and use Adjusted later for economic scaling if you need it. (This point is emphasized in the recommendations and reconciliation discussion.)
- Do not skip the shared as-of window. The later vintage should contain more rows (backfills). If you don’t cut it back to the earlier information set, your "B-only" count commingles real growth with timing.
Why editors and reviewers will care
- Replication risk: A project that merges on VALUE or timestamps can unintentionally turn a 0.7% true residual into 10% "anonymization," which will show up in dispersion, consensus, and "beat by a penny" statistics. Showing a stable key and a reason-coded diagnostic will make your methods section fast to review.
- Identification: When a residual is real, it is usually structured, non-US, certain horizons, or years where anonymization surged (starting 2017Q1). Labeling those buckets allows clean heterogeneity and robustness instead of sweeping them under the rug. (See Figure 1, Table 2.)
- Practical payoffs: Recommendations were largely stable. That opens practical cross-checks (and, where appropriate, partial recovery of anonymized IDs). It’s a direct benefit to researchers who need analyst-level panels. (See Table 3 and Table 4.)
- Myth-busting: Claims of ubiquitous reshuffling are inconsistent with the evidence across well-separated vintages. Reassignments are limited and mainly tied to previously anonymized rows or clerical errors that were later backfilled or rectified. (Table 5 and surrounding text.) The workflow above makes that easy to demonstrate rather than debate.
Attribution table
After your main merge, run a three-line attribution table. Each row shows the share of non-matches resolved when you apply the step:
- ±1-day estimate-date tolerance (timestamp refinement)
- Drop ANALYS (consensus-level identity)
- Hybrid firm id (CUSIP/SEDOL hygiene)
An optional addition is FPI recoding check (are non-matches concentrated in specific horizon codes?) and an "older vs. newer years" split. This triage turns vague "data drift" into labeled mechanisms and mirrors best practice on documented structural changes and their timing.
FAQ (what your RAs will ask)
Q1. Why is STATPERS preferred to ANNDATS?
Because STATPERS represents when the estimate is on the tape from the database’s perspective. It aligns with the "information set" you want to hold fixed across vintages. If STATPERS is missing, use ANNDATS and document that choice.
Q2. Can I do this at the consensus level?
Yes. Use { firm, FPEDATS, FPI, MEASURE, estimate_date } (drop ANALYS). Just remember: if consensus merges beautifully but analyst-level does not, your issue is the ID layer (anonymization/maintenance), not event identity. (That asymmetry is exactly what you’d expect post-2017 outside the US.)
Q3. What about recommendations and price targets?
Recommendations are largely unaffected by the anonymization pattern that hits forecasts. They’re excellent for cross-checks and (in many cases) ID recovery. Price target reassignment is rare and often looks like corrections of names, not substantive changes. (See Table 3 and the discussion around the price-target file.)
Q4. Should I ever key on VALUE or currencies?
No, not for identity across vintages. Those are attributes, not identity. They legitimately change and will inflate false non-matches. Use them for analysis after you’ve matched events.
Q5. Are there "problem vintages" I should avoid?
Not at this moment. Be explicit about the download date you use. Avoid the ambiguous June-September 2019 window in point-in-time comparisons and follow the recommendations in the paper’s concluding section. (See "Recommendations" section.)
Final words
Adopt the two rules at the top. They prevent 90% of the pain when merging IBES vintage.
← Back to Good-bye I/B/E/S